COPY_TO_RELATIVE: PROCEDURE OPTIONS(MAIN);
%INCLUDE PARTLIST; /* Declaration of PARTLIST */ /* (1) */
DECLARE OLDFILE FILE INPUT RECORD SEQUENTIAL;
DECLARE RECORD_NUMBER FIXED BINARY;
DECLARE
PARTS FILE OUTPUT KEYED RECORD ENVIRONMENT(
MAXIMUM_RECORD_NUMBER(600), /* (2) */
FIXED_LENGTH_RECORDS,
MAXIMUM_RECORD_SIZE(36));
ON ENDFILE(OLDFILE) BEGIN; /* (3) */
CLOSE FILE(OLDFILE), FILE(PARTS);
STOP;
END;
OPEN FILE(OLDFILE), FILE(PARTS);
DO WHILE('1'B);
READ FILE(OLDFILE) INTO(PARTLIST); /* (4) */
RECORD_NUMBER = PARTLIST.NUMBER;
WRITE FILE(PARTS) FROM(PARTLIST) KEYFROM(RECORD_NUMBER); /* (5) */
END;
END COPY_TO_RELATIVE;
|
Records in this file can subsequently be accessed either sequentially or by part number. To access a record by part number, you specify the number as a key. For example:
GET LIST(INPUT_NUMBER) OPTIONS(PROMPT('Part? '));
READ FILE(PARTS) INTO(PARTLIST) KEY(INPUT_NUMBER);
|
Here, the value entered in response to the GET statement is used as a key value to access a record in the file.
In Example 6-1, the file PARTS is opened with the KEYED and OUTPUT attributes. When this program is executed, the amount of space allocated for the file PARTS depends on the relative record numbers of the records that are written to the file. For example, if the largest record number allowed for any record in the file is 600, but the largest record number specified for a record is 200, then RMS allocates only enough space for 200 records.
When you initially populate a file and you plan to fill the entire file through the maximum record number, you can cause RMS to use either of the following techniques to allocate space for the entire file:
- Specify the FILE_SIZE option to allocate space for the file when it is created.
- Write the record with the largest relative record number first. This will force RMS to allocate space for the entire file.
These techniques can optimize the throughput for the subsequent file additions, because RMS will not need to perform repeated extensions to the file as records are added.
To add or modify records in a relative file, open the file with the DIRECT and UPDATE attributes. For example, a procedure that updates the file PARTS when new stock is ordered might contain the following:
ORDER_PARTS: PROCEDURE (ORDERED_AMOUNT,PART_NUMBER);
%INCLUDE PARTLIST; /* Declaration of PARTLIST */
DECLARE (ORDERED_AMOUNT,PART_NUMBER) FIXED BIN(15);
DECLARE PARTS FILE RECORD DIRECT UPDATE;
OPEN FILE(PARTS);
READ FILE(PARTS) INTO(PARTLIST)
KEY(PART_NUMBER);
PARTLIST.ON_ORDER = PARTLIST.ON_ORDER +
ORDERED_AMOUNT;
REWRITE FILE(PARTS) FROM(PARTLIST);
CLOSE FILE(PARTS);
END;
|
In this example, the procedure ORDER_PARTS receives as its parameters the order quantity and the part number. It reads the record associated with the part number from the file, adds the order quantity to the existing quantity, and rewrites the record.
Reading a Relative File Sequentially
You can access a relative file sequentially as well as by key. When you access the file sequentially, each READ statement returns the record in the next cell that contains a record, skipping empty cells. The following example illustrates reading a relative file sequentially:
PRINT_PART: PROCEDURE OPTIONS(MAIN);
%INCLUDE PARTLIST; /* Declaration of PARTLIST */
DECLARE PARTS FILE,
CHECK_NUM FIXED;
DECLARE EOF BIT(1) ALIGNED INIT('0'B);
OPEN FILE(PARTS) INPUT SEQUENTIAL RECORD KEYED;
ON ENDFILE(PARTS) EOF = '1'B;
READ FILE(PARTS) INTO(PARTLIST) KEYTO(CHECK_NUM);
DO WHILE (^EOF);
PUT SKIP EDIT(PARTLIST.NAME, /* Output data */
UNIT_PRICE,
IN_STOCK,
ON_ORDER)
(A,X,A,X,A,X,A);
PUT SKIP EDIT('Relative record number',CHECK_NUM,
'Part number:',PARTLIST.NUMBER)
(X(10),A,X,F(5),A,X,A); /* Output
verification */
READ FILE(PARTS) INTO(PARTLIST) KEYTO(CHECK_NUM);
END;
|
This procedure outputs the contents of the file PARTS, listing each
field in the data records described by PARTLIST. The READ statement
specifies the KEYTO option; the procedure outputs the value returned to
the variable CHECK_NUM.
6.6.4 Error Handling
PL/I signals the KEY condition when errors occur during the processing of record numbers for relative files. For example, it signals the KEY condition when a relative record number exceeds the maximum record number specified for the file, or when the number of a record that already exists is specified in a KEYFROM option in a WRITE statement.
The following sample ON-unit shows how to detect whether a record already exists in a relative file or whether a record number specified exceeds the file's maximum record number.
ON KEY(PARTS) BEGIN;
%INCLUDE $RMSDEF;
/* Check for duplicate records */
IF ONCODE() = RMS$_REX /* If duplicate */
THEN DO;
PUT SKIP EDIT('Part number',
PARTLIST.NUMBER,'exists. Reenter')
(A,X,A,X,A);
GET LIST(PARTLIST.NUMBER); /* Get new value */
GOTO GET_DATA; /* Go get other data */
END;
/* Check for maximum record number exceeded */
ELSE
IF ONCODE = RMS$_MRN
THEN DO;
PUT SKIP EDIT('Part number',PARTLIST.NUMBER,
'invalid. Reenter')
(A,X,A,X,A);
GET LIST(PARTLIST.NUMBER); /* Get new value */
GOTO GET_DATA; /* Go get other info */
END;
END;
.
.
.
GET_DATA:
|
In this example, the ON-unit sets symbolic names for two specific status values returned by ONCODE, from PLI$STARLET:
- The value RMS$_REX indicates that a record already exists.
- The value RMS$_MRN indicates that a relative record number specified exceeds the maximum record number.
In an ON-unit for the KEY condition for a relative file, ONCODE can also return the values associated with the following status codes:
- RMS$_RNF indicates that there is no record in the file with the relative record number specified by a KEY option.
- RMS$_KEY indicates that a key value is invalid, for example, if it is not an integer.
6.7 Indexed Sequential Files
This section describes the organization of indexed sequential files,
suggests considerations for creating and using them, and shows examples
of some typical operations.
6.7.1 Indexed File Organization
In an indexed sequential file, the file contains data records and pointers to the records. Data records and record pointers are arranged in buckets, which consist of an integral number of physically contiguous 512-byte disk blocks. Individual records within the file are located by the specification of the keys (indexes) associated with the records. Each file must have a primary key-that is, a field within the record that has a unique value to distinguish it from all other records in the file. An indexed sequential file can also have up to 254 alternate keys, which need not have unique values.
RMS writes records to an indexed file in collating sequence according to the primary key, putting them in buckets that are chained together. Thus, an individual file can be accessed sequentially with any key.
Figure 6-2 illustrates an indexed sequential file with a single key.
Figure 6-2 An Indexed Sequential File
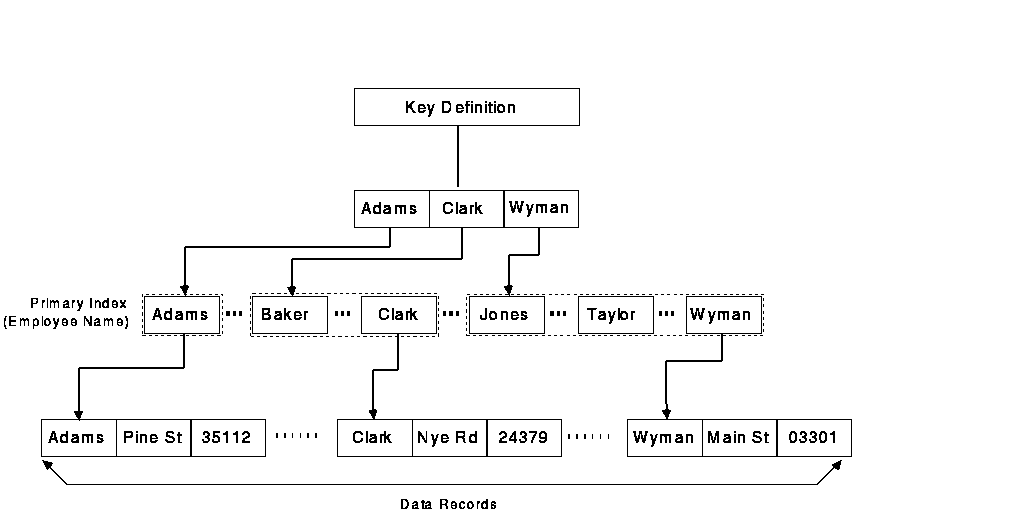
The records in the file illustrated in Figure 6-2 consist of address data that might have been defined in a PL/I structure as follows:
DECLARE 1
ADDRESS_FILE,
2 EMPLOYEE_NAME CHARACTER(30),
2 ADDRESS,
3 STREET CHARACTER(20),
3 ZIP_CODE CHARACTER(5);
|
In this file, the key is the employee name.
When RMS writes records to an indexed sequential file, it builds and maintains a tree-like structure of key values and location pointers. When records are accessed by key, RMS uses the tree to locate individual records. Thus, when a PL/I program accesses the record whose key value is JONES, RMS traverses the indexes to locate the record.
When new records are added to an indexed sequential file, a data bucket
may not have enough room to accommodate a new record. In this case, RMS
performs what is called bucket splitting: it inserts a new bucket in
the chain of data buckets and moves enough records from the previous
bucket to preserve the primary key sequence. Bucket splitting is
transparent to the PL/I program; the program knows only that it has
added a record to the file.
6.7.2 Defining and Creating an Indexed Sequential File
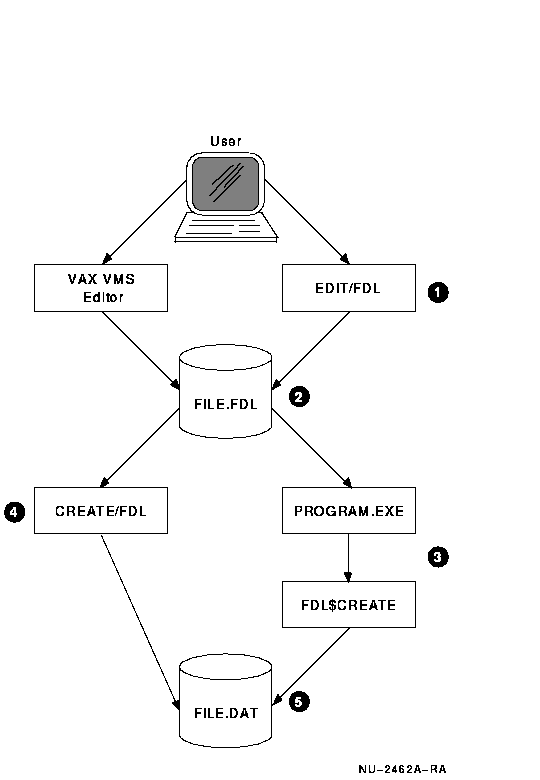
As shown in Figure 6-3, an indexed sequential file must first be defined, then created. You define the characteristics of your indexed sequential file using the Open File Definition Language (FDL), and then use that definition (the resulting FDL file) to create the indexed sequential file for use by your program.
You can use several methods to create an FDL definition file: an OpenVMS editor, a PL/I program, or the FDL Facility. The following steps are keyed to the callout numbers in Figure 6-3.
- Use an editor to describe the data file.
- An FDL language source file defines the data file.
- You can use a program to create an FDL language source file and call FDL$CREATE to create a data file.
- You can use FDL to create a data file.
- The data file is created.
Figure 6-3 Creating a Data File
The following sections explain how to create a definition file by using
the FDL Facility and how to create one through a PL/I program.
6.7.2.1 Using EDIT/FDL
You can use the command EDIT/FDL to define an indexed sequential file for PL/I. Note that while you can construct FDL file specifications using any of the OpenVMS text editors, the FDL Facility gives you the added convenience of systematic prompting for and automatic formatting of the specifications. The specifications are written in the File Definition Language (FDL) and the files are referred to as FDL files.
The FDL Facility is interactive: it prompts you to enter data and responds with error messages when you enter data incorrectly. It supplies many default values. The only data that you must specify is as follows:
- The file name of the file you are creating
- The word INDEXED, to indicate that the file is an indexed sequential file
- The number of records that will initially be loaded into the file
- The mean record size
- The size of the key
You can obtain help by pressing RETURN in response to the first menu. Each item on the menu leads to another menu in the specification of the data file. You can return to the original menu by pressing Ctrl/z.
$ EDIT/FDL [Return]
_File: STATE50 [Return]
Parsing Definition File
DBA0:[SMITH]STATE50.FDL; will be created.
Press return to continue (^Z for Main Menu)[Return]
OpenVMS FDL Editor
Add to insert one or more lines into the FDL definition
Delete to remove one or more lines from the FDL definition
Exit to leave the FDL Editor after creating the FDL file
Help to obtain information about the FDL Editor
Invoke to initiate a script of related questions
Modify to change existing line(s) in the FDL definition
Quit to abort the FDL Editor with no FDL file creation
Set to specify FDL Editor characteristics
View to display the current FDL definition
Main Editor Function (Keyword)[Help]:INVOKE [Return]
|
FDL displays further menus to guide you through the creation of the file.
After you define your data file, FDL displays a message like the following, giving the file specification of the definition file:
DBA0:[SMITH]STATE50.FDL;1 40 lines |
FDL formats the information that you supply so that it can be used to create an indexed sequential file. However, you can also use EDT or any other OpenVMS text editor to design an FDL text.
FDL allows you to specify many characteristics for your file, but requires you to specify only a limited number. The following example, written in FDL, illustrates some of the possible file characteristics. The explanatory comments to the right would not appear in an FDL file; they have been added for your information.
SYSTEM
SOURCE VAX/VMS
FILE
NAME state50.dat /* file name */
ORGANIZATION indexed
RECORD
CARRIAGE_CONTROL carriage_return
FORMAT fixed /* record attributes */
SIZE 60
AREA 0
ALLOCATION 25 /* number of blocks */
BEST_TRY_CONTIGUOUS yes /* as close as possible */
BUCKET_SIZE 2 /* number of blocks in record */
EXTENSION 2 /* blocks for extension */
AREA 1
ALLOCATION 3
BEST_TRY_CONTIGUOUS yes
BUCKET_SIZE 2
EXTENSION 0
AREA 2
.
.
.
AREA 7
ALLOCATION 2
BEST_TRY_CONTIGUOUS yes
BUCKET_SIZE 1
EXTENSION 0
KEY 0 /* primary key */
CHANGES no /* cannot be changed */
DATA_AREA 0 /* data in AREA 0 */
DATA_FILL 100 /* %fill for data */
DUPLICATES no /* not allowed */
INDEX_AREA 1 /* index in AREA 1 */
INDEX_FILL 100 /* %fill for index */
LEVEL1_INDEX_AREA 1 /* level-1 index in AREA 1 */
PROLOGUE 2 /* type for index */
SEG0_LENGTH 20 /* key length */
SEG0_POSITION 0 /* key position */
TYPE string /* character string */
.
.
.
KEY 3 /* third alternate key */
CHANGES yes
DATA_AREA 6
DATA_FILL 100
DUPLICATES yes
INDEX_AREA 7
INDEX_FILL 100
LEVEL1_INDEX_AREA 7
SEG0_LENGTH 3
SEG1_LENGTH 3
SEG2_LENGTH 3
SEG0_POSITION 0
SEG1_POSITION 20
SEG2_POSITION 40
TYPE string
|
After creating an FDL file with EDIT/FDL or a text editor, you can then
use the command CREATE/FDL, which uses the specifications in the FDL
file to create a new, empty data file. Thus, you can use EDIT/FDL to
define the data file, and then create the data file when it is required
later. See the OpenVMS File Definition Language Facility Reference Manual for further details.
6.7.2.2 Using a PL/I Program
You can write a PL/I program to define an indexed sequential file or to create an indexed sequential file from an existing definition, or both. The following lines in the program enable the optional generation of a file definition and the use of that definition to create a file:
%INCLUDE FDL$CREATE;
.
.
.
CALL FDL$CREATE ('STATE50.FDL');
|
The following program, CREATE50, defines a file similar to the file defined with the FDL Facility in Section 6.7.2.1.
CREATE50: PROCEDURE OPTIONS(MAIN);
DECLARE ANSWER CHAR(1); /* answer variable */
DECLARE (I,J) FIXED BIN(31); /*index control variables */
%INCLUDE FDL$CREATE;
/* default allocation, bucket size, and extent for each area */
DECLARE AREA_ATTRIBUTES(0:7,0:2) FIXED BIN(7) STATIC INITIAL (
25, 2, 2,
2, 2, 0,
15, 2, 1,
3, 2, 0,
20, 2, 2,
3, 2, 0,
9, 1, 0,
7, 1, 0);
/* default areas, fills, segment lengths, and positions for each key */
DECLARE KEY_ATTRIBUTES(0:3,0:10) FIXED BIN(7) STATIC INITIAL (
0, 100, 1, 100, 1, 20, 0, 0, 0, 0, 0,
2, 100, 3, 100, 3, 20, 0, 0, 20, 0, 0,
4, 100, 5, 100, 5, 20, 0, 0, 40, 0, 0,
6, 100, 7, 100, 7, 3, 3, 3, 0, 20, 40);
/* FDL file that will be created if necessary */
DECLARE FDL FILE PRINT OUTPUT;
/* find out if FDL file already exists */
GET LIST (ANSWER)
OPTIONS(PROMPT('Have you already created STATE50.FDL
with EDIT/FDL or EDT? '));
/* file definition (.FDL) file creation */
IF ANSWER = 'N' | ANSWER = 'n'
THEN
DO;
PUT SKIP LIST (' Creating STATE50.FDL.....');
OPEN FILE (FDL) TITLE ('state50.fdl') PAGESIZE(32767);
/* define system */
PUT SKIP FILE (FDL) LIST ('SYSTEM');
PUT SKIP FILE (FDL) LIST (' SOURCE VAX/VMS');
/* define file */
PUT SKIP FILE (FDL) LIST ('FILE');
PUT SKIP FILE (FDL) LIST (' NAME state50.dat');
PUT SKIP FILE (FDL) LIST (' ORGANIZATION indexed');
/* define record */
PUT SKIP FILE (FDL) LIST ('RECORD');
PUT SKIP FILE (FDL) LIST (' CARRIAGE_CONTROL carriage_return');
PUT SKIP FILE (FDL) LIST (' FORMAT fixed');
PUT SKIP FILE (FDL) LIST (' SIZE 60');
/* define areas */
DO I = 0 TO HBOUND (AREA_ATTRIBUTES,1);
PUT SKIP FILE (FDL) LIST ('AREA '||trim(character(i)));
PUT SKIP FILE (FDL) LIST (' ALLOCATION '||
character(area_attributes(i,0)));
PUT SKIP FILE (FDL) LIST (' BEST_TRY_CONTIGUOUS yes');
PUT SKIP FILE (FDL) LIST (' BUCKET_SIZE '||
character(area_attributes(i,1)));
PUT SKIP FILE (FDL) LIST (' EXTENSION '||
character(area_attributes(i,2)));
END;
/* define keys */
DO I = 0 TO HBOUND (KEY_ATTRIBUTES,1);
PUT SKIP FILE (FDL) LIST ('KEY '||TRIM(CHARACTER(I)));
IF I = 0 THEN PUT SKIP FILE (FDL) LIST (' CHANGES no');
ELSE PUT SKIP FILE (FDL) LIST (' CHANGES yes');
PUT SKIP FILE (FDL) LIST (' DATA_AREA '||
CHARACTER(KEY_ATTRIBUTES(I,0)));
PUT SKIP FILE (FDL) LIST (' DATA_FILL '||
CHARACTER(KEY_ATTRIBUTES(I,1)));
IF I = 0 THEN PUT SKIP FILE (FDL) LIST (' DUPLICATES no');
ELSE PUT SKIP FILE (FDL) LIST (' DUPLICATES yes');
PUT SKIP FILE (FDL) LIST (' INDEX_AREA '||
CHARACTER(KEY_ATTRIBUTES(I,2)));
PUT SKIP FILE (FDL) LIST (' INDEX_FILL '||
CHARACTER(KEY_ATTRIBUTES(I,3)));
PUT SKIP FILE (FDL) LIST (' LEVEL1_INDEX_AREA '||
CHARACTER(KEY_ATTRIBUTES(I,4)));
DO J = 0 TO 2;
IF KEY_ATTRIBUTES(I,5+J*2) ^= 0
THEN DO;
PUT SKIP FILE (FDL) LIST (' SEG'||TRIM(CHARACTER(J))||'_LENGTH '||
CHARACTER(KEY_ATTRIBUTES(I,5+J*2)));
PUT SKIP FILE (FDL) LIST (' SEG'||trim(character(j))||'_POSITION '||
CHARACTER(KEY_ATTRIBUTES(I,5+J*2)));
END;
END;
PUT SKIP FILE (FDL) LIST (' TYPE string');
END;
CLOSE FILE (FDL);
END;
/* create STATE50.DAT using STATE50.FDL as the definition file */
PUT SKIP LIST (' Creating file using STATE50.FDL.....');
CALL FDL$CREATE ('STATE50.FDL');
END CREATE50;
|
This program uses the same FDL statements that would be used if you had issued the EDIT/FDL command. Notice that the program asks you whether you have already created the file and, if so, calls FDL$CREATE, which permits you to use a preexisting file definition.
Note that the following command:
$ CREATE/FDL=STATE50 |
is equivalent to the following command and response:
$ RUN CREATE50 Have you already created STATE50.FDL with EDIT/FDL or EDT? Y |
| Previous | Next | Contents | Index |