| Previous | Contents | Index |
Arithmetic data types are used for variables on which arithmetic calculations are to be performed. The arithmetic data types supported by PL/I are as follows:
When you declare an arithmetic variable, you do not always have to define all its characteristics, or attributes.
Table 3-1 shows the implied attributes for computational data.
3.2.1 Precision and Scale of Arithmetic Data Types
The PRECISION attribute applies to decimal and binary data as follows:
The scale of fixed-point data is the number of digits to the right of the decimal or binary point. Floating-point variables do not have a scale factor. In this manual, the letter p is used to indicate precision, and the letter q is used to indicate the scale factor.
You can specify both precision and scale in a declaration. For example:
DECLARE x FIXED DECIMAL(10,3) INITIAL(1.234); |
This example indicates that the value of x has 10 decimal digits and that 3 of those are fractional. When a value is assigned to the variable, its internal representation does not include the decimal point; the previous value for x is stored as 1234, and the decimal point is inserted when the number is output. The scale factor has the effect of multiplying the internal representation of the decimal number by a factor of 10-q (where q is the absolute value of the specified scale).
The ranges of values you can specify for the precision for each arithmetic data type, and the defaults applied if you do not specify a precision, are summarized as follows:
| Data Type Attributes |
Precision |
Scale Factor |
Default Precision |
|---|---|---|---|
| BINARY FIXED | 1 <= p <= 31 | p >= q >= -31 | 31 |
| BINARY FLOAT (OpenVMS VAX systems) | 1 <= p <= 113 | - | 24 |
| BINARY FLOAT (OpenVMS Alpha systems) | 1 <= p <= 53 | - | 24 |
| DECIMAL FIXED | 1 <= p <= 31 | p >= q >= 0 | 10 |
| DECIMAL FLOAT (OpenVMS VAX systems) | 1 <= p <= 34 | - | 7 |
| DECIMAL FLOAT (OpenVMS Alpha systems) | 1 <= p <= 15 | - | 7 |
If no scale factor is specified for fixed-point data, the default is 0.
For fixed-point binary data, the scale factor must be within the range -31 through 31 and less than or equal to the specified precision. Positive scale factors for fixed binary numbers function according to the same principles as those for fixed decimal. That is, a positive scale factor is similar to multiplying the internal representation binary number by a factor of 2-q.
A negative scale factor indicates that the number of fractional bits are shifted in the opposite direction. In effect, this is similar to multiplying the binary number by a factor of 2q, where q is the absolute value of the specified scale. For example:
DECLARE (A,B) FIXED BINARY(31,-3),
(C,D) FIXED BINARY(31,3);
A = 128; /* output = 128 */
B = 7; /* output = 0 */
C = 128; /* output = 128.0 */
D = 7; /* output = 7.0 */
PUT SKIP LIST (A,B,C,D);
END;
|
Internally, binary numbers undergo an implicit conversion and are represented as powers of 2. For instance, in the previous example variable A is first divided by 23 because it is declared with a scale factor of -3. The stored number is 16. On output, the number 16 is multiplied by 23 and the number is again 128. However, when variable B is first divided by 23, the result is 0, which is the value of the stored number. Therefore, on output, 0 is multiplied by 23 and the output is 0.
Integer variables declared in the previous example with a positive scale factor are output as they were input, but they are followed on the right with a decimal point and a 0.
Even though arithmetic operands can be of different arithmetic types, all operations must be performed on objects of the same type. Consequently, the compiler can convert operands to a derived type, as previously shown. Therefore, when you declare a fixed binary number with a scale factor and assign it a decimal value, the results may not be as you expect because the binary scale factor left-shifts the specified number of bits to the right of the decimal point. During conversion to a decimal representation, the difference between the resulting binary number and its decimal representation is not the equivalent of dividing or multiplying the decimal number by 10. Instead, the binary number is first converted to its internal representation and then this representation is converted to its decimal representation.
When excess fractional digits are truncated, no condition is signaled. If there is any resulting loss of precision, it may be difficult to detect because truncated fractional digits do not signal a condition.
For example:
A: PROCEDURE OPTIONS (MAIN);
DECLARE A FIXED BIN (31,3),
B DECIMAL (10,5),
C DECIMAL (10,5);
A = .3;
B = 34.8;
C = MULTIPLY(A,B,10,5);
PUT SKIP LIST (A,B,C);
END;
|
Before the multiplication is performed, the variables are converted to fixed binary so that the operands share a common data type. However, after conversion, variable A is output as 0.2 rather than 0.3. The output from the previous example is:
0.2 34.80000 8.6875 |
If variable A was declared with the attributes FIXED DECIMAL (10,5), the output will be:
0.30000 34.80000 10.44000 |
The attributes FIXED and BINARY are used to declare integer variables and fractional variables in which the number of fractional digits is fixed (that is, nonfloating-point numbers). The BINARY attribute is implied by FIXED.
For example, a fixed-point binary variable can be declared as:
DECLARE X FIXED BINARY(31,0); |
There is no representation in PL/I for a fixed-point binary constant. Instead, integer constants are represented as fixed decimal. However, fixed decimal integer constants (and variables) are converted to fixed binary when combined with fixed binary variables in expressions. For example:
I = I+3; |
In this example, if I is a fixed binary variable, the integer 3 is represented as fixed decimal; however, PL/I converts it to fixed binary when evaluating the expression.
Fixed binary variables have a maximum precision of 31, and therefore fixed binary integers can have values only in the range -2,147,483,648 through 2,147,483,647. An attempt to calculate a binary integer outside this range, in a context that requires an integer value, signals the FIXEDOVERFLOW condition.
The attributes FIXED BINARY are used to declare binary data in PL/I. The BINARY attribute is implied by FIXED. The format of a declaration of a single, fixed-point, binary variable is:
DECLARE identifier FIXED [BINARY] [(precision[,scale-factor])]; |
There is no form for a fixed-point binary constant, although constants
of other computational types are convertible to fixed-point binary. A
fixed-point binary variable usually receives given values by being
assigned to an expression of another computational type or another
fixed-point binary variable.
3.2.2.1 Internal Representation of Fixed-Point Binary Data
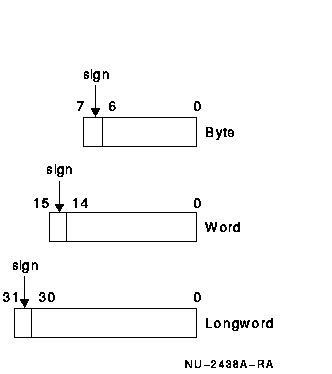
Figure 3-1 shows the internal representation of fixed-point binary data. Storage for fixed-point binary variables is always allocated in a byte, word, or longword. For any fixed-point binary value:
The binary digits of the stored value go from right to left in order of increasing significance; for example, bit 6 of a FIXED BINARY (7) value is the most significant bit, and bit 0 is the least signficant.
In all cases, the high-order bit (7, 15, or 31) represents the sign.
Figure 3-1 Internal Representation of Fixed-Point Binary Data
Fixed-point decimal data is used in calculations where exact decimal values must be maintained, for example, in financial applications. You can also use fixed-point decimal data with a scale factor of 0 whenever integer data is required.
The following sections describe fixed-point constants and variables and their use in expressions.
This discussion is divided into the following parts:
A fixed-point decimal constant can have between 1 and 31 of the decimal digits 0 through 9 with an optional decimal point or sign, or both. If there is no decimal point, PL/I assumes it to be immediately to the right of the rightmost digit. Some examples of fixed-point decimal constants are:
12 4.56 12345.54 -2 01. |
The precision of a fixed-point decimal value is the total number of
digits in the value. The scale factor is the number of digits to the
right of the decimal point, if any. The scale factor cannot be greater
than the precision.
3.2.3.2 Fixed-Point Decimal Variables
The attributes FIXED and DECIMAL are used to declare fixed-point decimal variables. The FIXED attribute is implied by DECIMAL.
If you do not specify the precision and the scale factor, the default values are 10 and 0, respectively.
The format of a declaration of a single fixed-point decimal variable is:
DECLARE identifier [FIXED] DECIMAL [(p[,q])]; |
Some examples of fixed-point decimal declarations are:
DECLARE PERCENTAGE FIXED DECIMAL (5,2); DECLARE TONNAGE FIXED DECIMAL (9); |
You cannot use fixed-point decimal data with a nonzero scale factor in calculations with binary integer variables. If you must use the two types of data together, use the DECIMAL built-in function to convert the binary value to a scaled decimal value before attempting an arithmetic operation. For example:
DECLARE I FIXED BINARY,
SUM FIXED DECIMAL (10,2);
SUM = SUM + DECIMAL (I);
|
Fixed-point decimal data is stored in packed decimal format. Each digit is stored in a half-byte, as shown in Figure 3-2. Bits 0 through 3 of the last half-byte contain a value indicating the sign. Normally, the hexadecimal value C indicates a positive value and the hexadecimal value D indicates a negative value.
Figure 3-2 Fixed-Point Decimal Data Representation

The floating-point data types provide a way to express very large and very small numbers such as in scientific calculations. All floating-point calculations are performed on values in one of the binary floating-point formats. In general, the precision of the result is determined by the maximum precision of any operands in the operation. The numerical result of an operation is rounded to the result precision.
The following sections describe floating-point constants and variables and their use in expressions.
This discussion of floating-point data is divided into the following parts:
A floating-point constant can have one or more of the decimal digits 0 through 9 (with an optional decimal point), followed by the letter E and from one to five decimal digits representing a power of 10. The floating-point value and the integer exponent can both be signed. The first portion of the value, to the left of the letter E, is called the mantissa. The value to the right of the letter E is called the exponent.
Some examples of floating-point constants are:
2E10 -3E8 32E-8 .45632E16 |
The decimal precision of each of these values is the number of digits in the mantissa.
If you write a constant without the E and the exponent, it is considered to be fixed-point decimal. However, you can use such constants anywhere in expressions involving floating-point data.
All floating-point constants are decimal.
3.2.4.2 Floating-Point Variables
The keyword FLOAT identifies a floating-point variable in a declaration.
A floating-point value can be either binary or decimal. Because the internal representation of floating-point variables is binary, it is recommended that you use FLOAT BINARY (which is the default) to declare variables, unless you need the properties of FLOAT DECIMAL. (The difference between FLOAT BINARY and FLOAT DECIMAL appears only when a conversion to another type, such as character, for doing I/O is necessary.) You should declare all floating-point variables using the same base.
To declare a single floating-point binary variable, specify a DECLARE statement as follows:
DECLARE identifier FLOAT [BINARY] [(p)]; |
You can optionally specify the precision for a floating-point variable in the declaration. For example:
DECLARE X FLOAT BINARY(53); |
The keyword FLOAT identifies a floating-point variable.
To declare a decimal floating-point variable, use the following format:
DECLARE identifier FLOAT DECIMAL [(p)]; |
For example:
DECLARE X FLOAT DECIMAL (30); |
You can use both integer and scaled decimal constants in floating-point expressions. An arithmetic constant is always converted to the appropriate internal representation for use in a floating-point operation. The target type for the conversion depends on the context. For example:
DECLARE X FLOAT BINARY (53); X = X + 1.3; |
Such a conversion is normally done during compilation, but in some
cases the constant is maintained in decimal until run time.
3.2.4.4 Floating-Point Data Formats
Table 3-2 summarizes the floating-point formats supported by the different implementations of PL/I.
| Implementation | Supported Formats |
|---|---|
| OpenVMS VAX systems | F, D, G, and H |
| OpenVMS Alpha systems | F, S, D, G, and T |
The S and T formats conform to the IEEE standards of floating-point formats.
Table 3-3 summarizes the approximate ranges of the floating-point formats.
| Format | Range |
|---|---|
| F or S | 0.29 * 10 -38 to 1.7 * 10 38 |
| D | Same as F but with a more precise mantissa (see Table 3-4) |
| G or T | 0.56 * 10 -308 to 0.9 * 10 308 |
| H | 0.84 * 10 -4932 to 0.59 * 10 4932 |
Table 3-4 summarizes the ranges of precision (sign bits, exponent bits, and fractional bits of accuracy) for each type. Section 3.2.4.5 and Section 3.2.4.6 describe the internal representation of floating-point data.
| Floating-Point Type1 | Sign Bits | Exponent Bits | Fractional Bits |
|---|---|---|---|
| F or S (single precision) | 1 | 8 | 24 |
| D (double precision) | 1 | 8 | 53 |
| G or T (double precision) | 1 | 11 | 53 |
| H (quadruple precision) | 1 | 15 | 113 |
The PL/I compiler selects the appropriate floating-point type based on the precision you specify and on a compile-time qualifier on the PLI command. The types are selected as shown in Table 3-5, where p indicates precision.
| Precision (DECIMAL) | Precision (BINARY) | OpenVMS VAX | OpenVMS Alpha |
|---|---|---|---|
| 1 <= p <= 7 | 1 <= p <= 24 | F | F or S 1 |
| 8 <= p <= 15 | 25 <= p <= 53 | D or G 2 | D, G, or T 3 |
| 16 <= p <= 34 | 54 <= p <= 113 | H | Warning |
In all VAX floating-point formats, the value 0 is indicated when the sign bit and all exponent bits are set to 0. In effect, this allows for the representation of a value with a 24-bit fraction and an 8-bit exponent in single precision, even though only 23 bits in the format are allocated for the fraction.
The double-precision and G-floating formats as used by PL/I have the same fractional precision; G-floating format allows an extra three bits for the exponent. The double-precision format has 56 bits available for the fraction, but only 53 bits are used by PL/I. If you specify a floating-point binary precision in the range 54 to 56, the numbers with this range of precision are represented by the H-floating format.
This small reduction in the precision of double-precision numbers is necessary to keep the compiler from selecting H-floating format on machines that lack the necessary hardware. The intent is to preserve the size of a structure containing double-precision data regardless of whether the G_FLOAT qualifier is used.
Figure 3-3 shows the internal structure of floating-point data for VAX systems. For a more detailed description of VAX floating-point formats, see the VAX Architecture Reference Manual.
Figure 3-3 VAX Internal Representation of Floating-Point Data

| Previous | Next | Contents | Index |